About
This is an active library, using C++ template metaprogramming, to automate loop parallelisation. This work has been done for my Ph.D. thesis.
Brief
It uses expression templates and an EDSL to build an AST of loops at compile-time. This AST is analysed to determine first which instructions of a given loop are interdependent, then for each instruction group if it can be run in parallel with itself at different iterations of the loop. The interdependence of instructions relies on how variables are accessed (read/write). To identify instruction groups that can be run in parallel, the library uses index functions (in array accesses) and a set of rules depending on these functions. According to this, the library generates sequential and/or parallel loops.
Example
Given this source code:
// a, b, c, d, e and f are arrays
for(int i = 0; i < n; ++i) {
a[i] = a[i] * b[i];
c[i] = c[i+1] - d[i];
b[i] = b[i] + i;
d[i] = std::pow(c[i], e[i]);
f[i*i] = 2 * f[i*i];
}
By writing it like this:
// a, b, c, d, e and f are expression template operands
// pow is an automatically generated expression template function
Index i;
parallelFor(Range{0, n},
a[i] = a[i] * b[i],
c[i] = c[i+ctv<1>] + d[i],
b[i] = b[i] + i,
d[i] = pow(c[i], e[i]),
f[injective(i*i)] = 2 * f[injective(i*i)]
);
The library will automatically produce these two loops:
for(int i = 0; i < n; ++i) {
c[i] = c[i+1] + d[i];
d[i] = std::pow(c[i], e[i]);
}
# pragma omp parallel for
for(int i = 0; i < n; ++i) {
a[i] = a[i] * b[i];
b[i] = b[i] + i;
f[i*i] = 2 * f[i*i];
}
Performances
Compilation time
This library runs mostly during the compilation and therefore extends its duration. We ran tests for four sets of source codes:
- "dep/fixed" corresponding to dependent instructions with common index functions;

- "indep/fixed" corresponding to independent instructions with common index functions;
- "dep/rand" corresponding to dependent instructions with random index functions;
- "indep/rand" corresponding to independent instructions with random index functions.
For more specific information, see the ctbenchmarks directory.
The compilation time is not significantly affected by the number of loops as shown below:
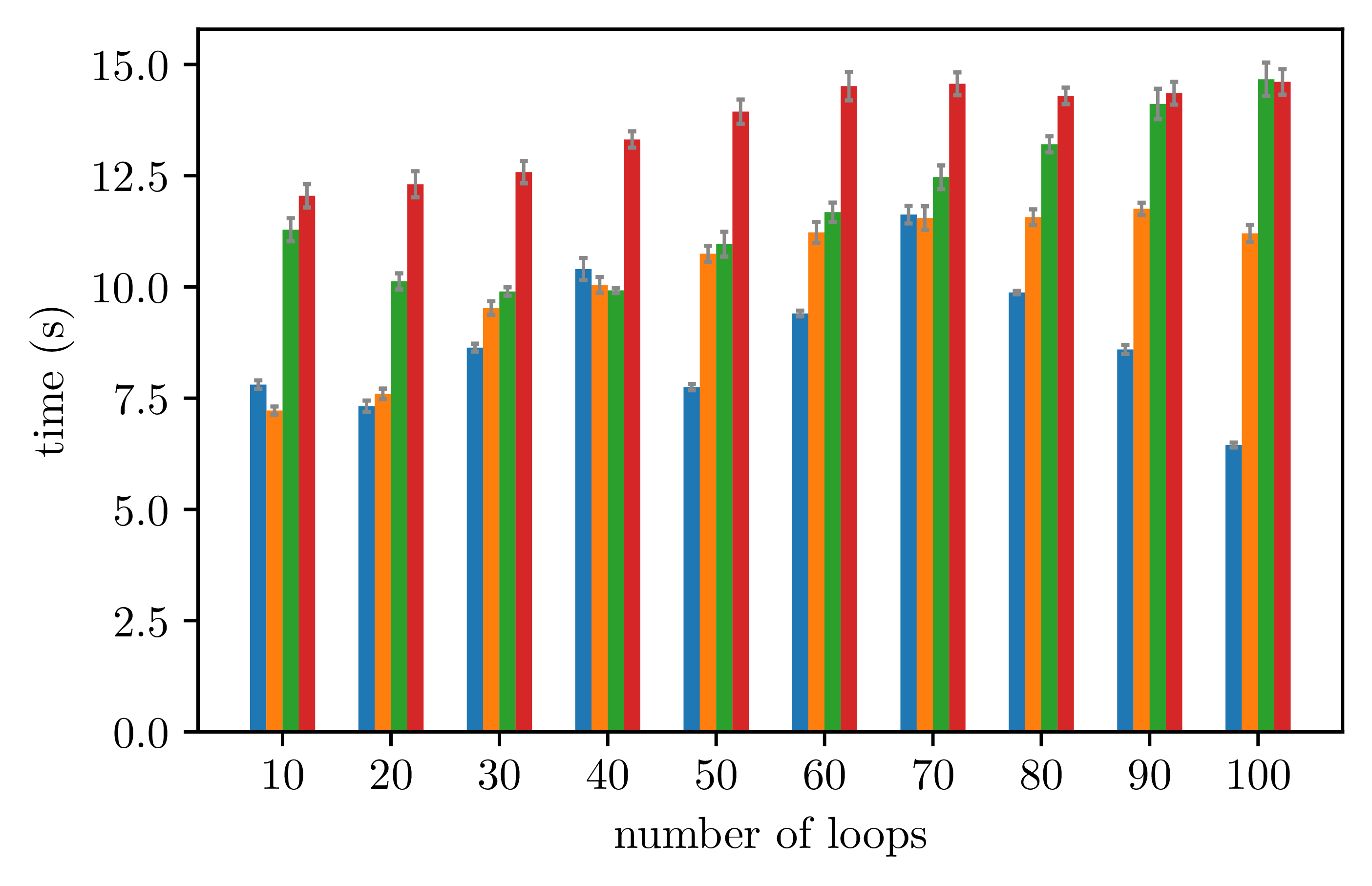
As expected, however, the compilation time increases (exponentially) with the number of instructions inside an unique loop:
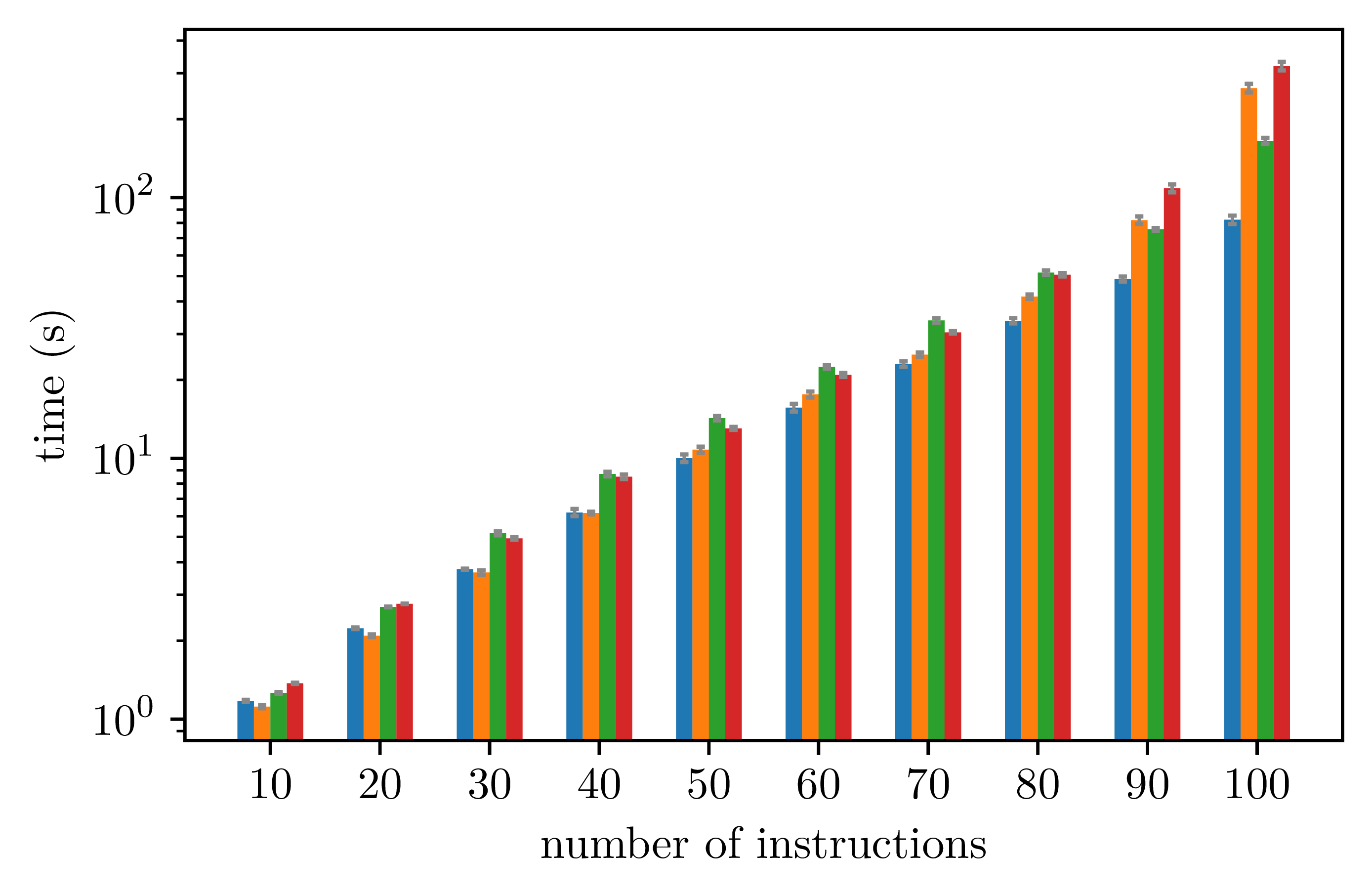
This could be improved but was not a priority as usually a single loop does not run so many instructions.
Execution time
The point of the library is to provide a solution to automatically run in parallel whenever possible, not to do better than what one can expect from classic parallelisation tools like OpenMP. In contrast, when a loop cannot be run in parallel, the library should not cause runtime overhead.
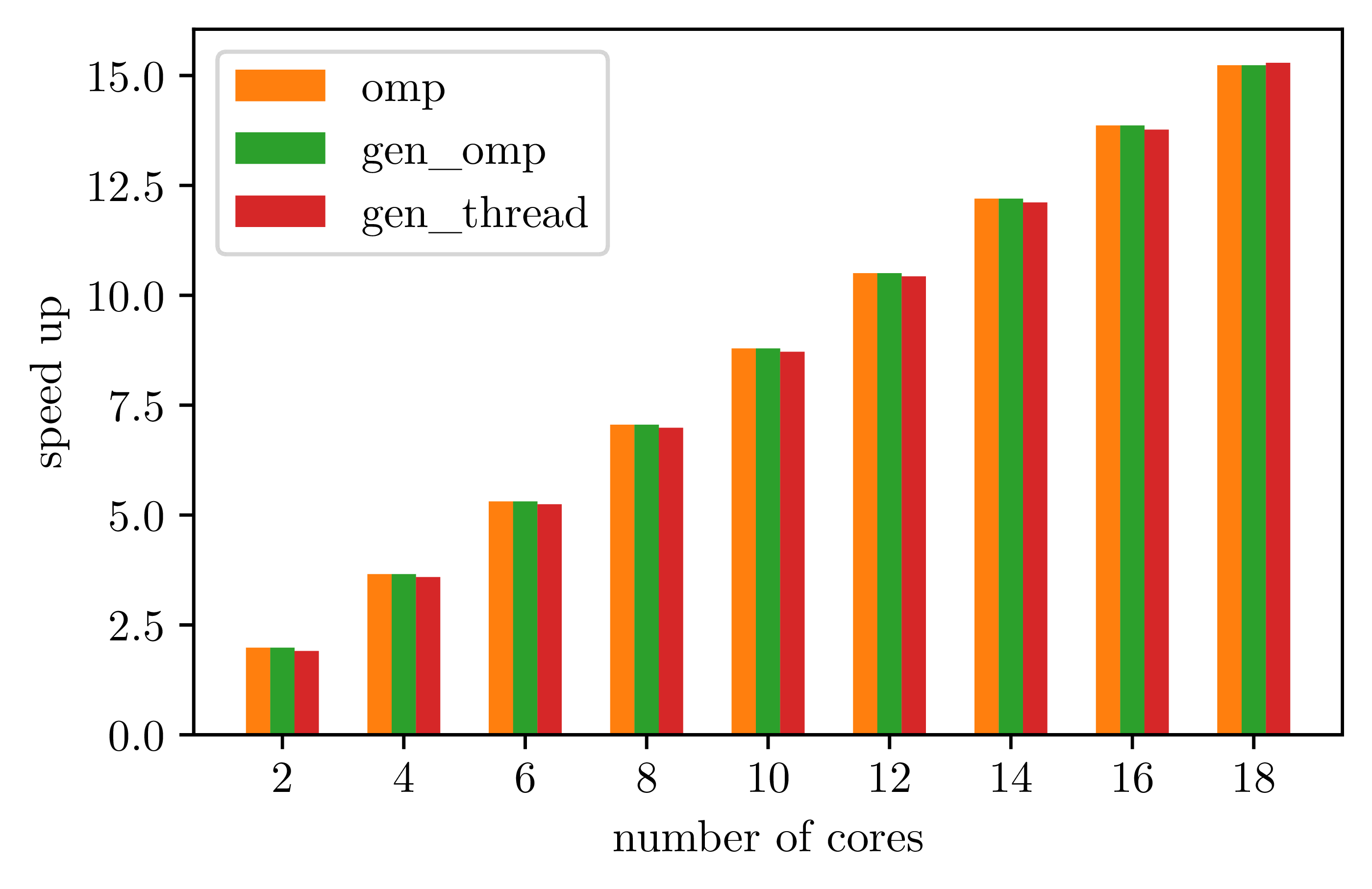
We ran tests with and without using the library:
- "seq" corresponding to a sequential execution without the library;

- "omp" corresponding to a parallel execution without the library, using OpenMP, when applicable;
- "gen_omp" corresponding to a parallel execution with the library generating OpenMP code;
- "gen_thread" corresponding to a parallel execution with the library generating multi-threaded loop.
For both "gen_omp" and "gen_thread", the library will actually generate a sequential code if the loop cannot be run in parallel.
The two figures below shows that using the library does not induce significant runtime overhead, both for sequential and parallel (with 18 cores) executions:
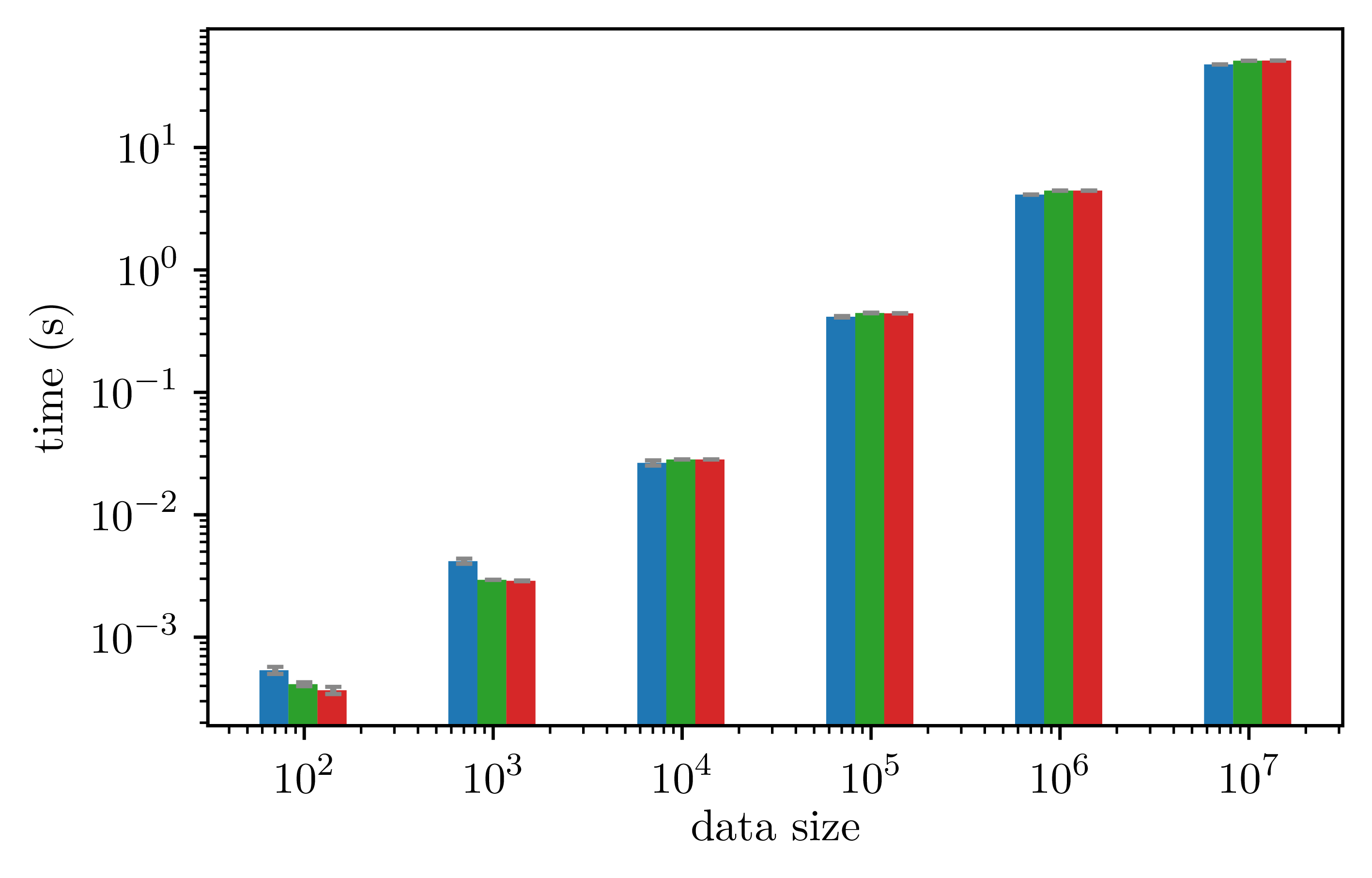
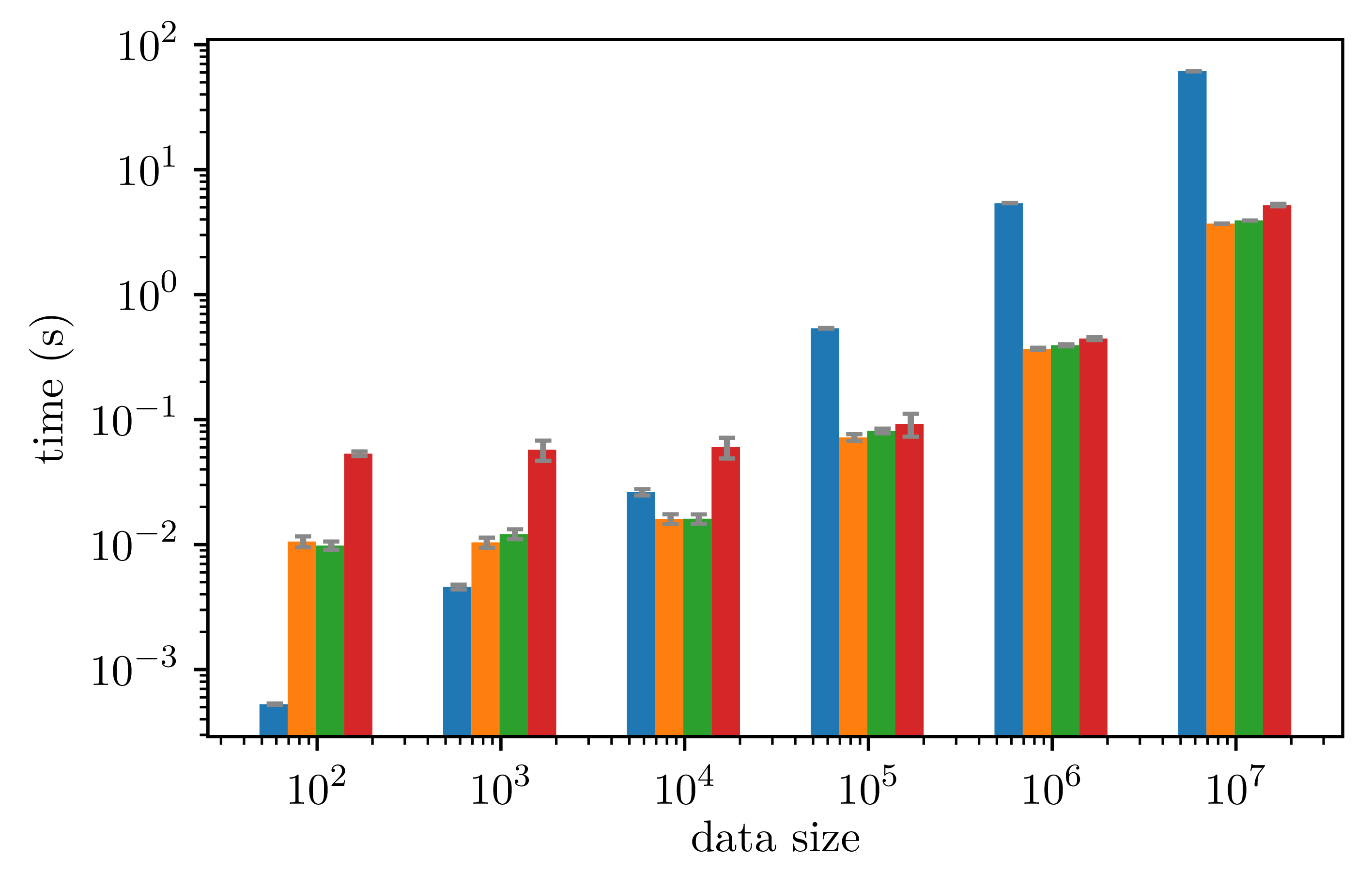
Obtained speed up is equivalent using the library with respect to a handwritten OpenMP program:
Related publications
- "Static Loop Parallelization Decision Using Template Metaprogramming", HPCS 2018 (IEEE) 10.1109/HPCS.2018.00159
Organisation
Main directories:
src/pfor: the library sources;examples: some examples using the library;[cr]tbenchmarks: scripts for compile-time/run-time benchmarking;results: results presented in the thesis, obtained using mentioned scripts and codes.
Usage
To produce the Makefile and build the project:
mkdir build
cd build
cmake -DCMAKE_BUILD_TYPE=Release ..
make
To run examples:
./build/examples/${example_name}